
































(大公報 記者 盧靜怡、吳俊宏)蛇年春節,廣東湛江吳川米歷嶺村沿路掛滿紅色歡迎橫幅,車水馬龍,熱鬧非凡。近段時間在海內外引發轟動的AI企業「深度求索」(DeepSeek)創始人、靈魂人物梁文鋒,便是來自這個小村子。近日,有消息指梁文鋒春節回老家過年,這個小村莊一夜間彷彿成為AI創新的朝聖地,不少遊客慕名前來「沾沾學霸氣息」。
梁文鋒的高中同學兼好友陳先生告訴媒體,梁文鋒年廿八(1月27日)下午還和舊時同學一起踢足球敘舊,除夕夜吃過年夜飯後,正月初一(1月29日)上午便已經離開。也許知道自己這幾天特別「火」,梁文鋒回朋友信息時打趣稱,今年回老家過年,可能要躲起來。

在米歷嶺村村口,一個平時用來作為婚禮現場裝飾的雙喜紅拱門被立了起來,寫着對聯:「文鋒回鄉傳佳績,鄉村振興添動力」,吸引不少家長帶着小朋友前來打卡。村中大紅橫幅隨處可見:「熱烈歡迎文鋒榮歸故里,家鄉因你而驕傲!」1月31日中午,該拱門已被低調拆下。
梁文鋒去年曾在一次訪問中談到,自己上世紀八十年代生長於廣東一個五線城市。「父親是小學老師,那時候很多家長覺得讀書沒用,甚至直接跑來家裏勸讓孩子不讀書。但如今再回頭看,一代人的時間,觀念就改變了。」梁文鋒堅定地說,相信以後硬核創新會越來越多。當社會讓創新者功成名就,群體性觀念自然會改變。「我們只是還需要一堆事實和一個過程。」
數學天賦驚人 「絕非書獃子」

梁文鋒初中班主任容老師告訴媒體,梁文鋒從小就是「尖子生」,數學天賦驚人。「他初中就學完高中數學,還自學大學課程。」容老師說,文鋒絕不是書獃子,他在學習上很有自己的一套方法,很注重勞逸結合,學好每一個學科彷彿毫不費力。
梁文鋒還特別喜歡踢足球。他的高中同學兼好友陳先生透露,梁文鋒年廿八下午還和舊時同學一起踢足球敘舊,除夕夜吃過年夜飯後,正月初一上午便已經離開。他們踢球時的合影已經在網上熱傳。照片中梁文鋒戴着眼鏡,穿着黃色的球服,笑容燦爛。
據介紹,2002年,梁文鋒以吳川市第一中學狀元的成績考上浙江大學。陳先生回憶稱,梁文鋒當時大學讀的AI工程專業前景並不明朗,但他很有前瞻的眼光,「完全是白手起家。」
梁文鋒2015年主導創立私募基金幻方量化,如今幻方量化管理着約80億美元資產,是內地最大的量化基金之一。2022年,幻方量化對外公布慈善捐贈情況,公司累計捐款近4億元人民幣,其中一筆1.38億元的匿名捐款署名「一隻平凡的小豬」。有媒體報道,在上海某慈善平台的付款紀錄上,這位匿名捐贈者的姓名是「梁*鋒」。「梁文鋒此前以個人名義在村裏捐了很多錢,每逢重陽節敬老他都一定會捐款。」陳先生說。
延續「狀元故里」傳統
在家鄉人眼裏,梁文鋒是當地「狀元」傳統的延續。吳川曾是粵西唯一的狀元故里,歷史上曾培養出1名狀元、20名進士、165名舉人。如今,這座小城又走出了一位全球矚目的科技創新者。
梁文鋒在2023年創立DeepSeek,向世界頂級科技巨頭發起挑戰。很短時間內,DeepSeek的開源AI模型風靡全球,「DeepSeek-V3」更被認為在性價比上超越了OpenAI的GPT-4o。新模型發布後,全球用戶蜂擁而至,春節前夕,梁文鋒才終於抽身回鄉,短暫休整,但假期不會太長,因為DeepSeek的下一代模型將啟動開發。節後梁文鋒將立即投入工作,繼續推動AI發展。
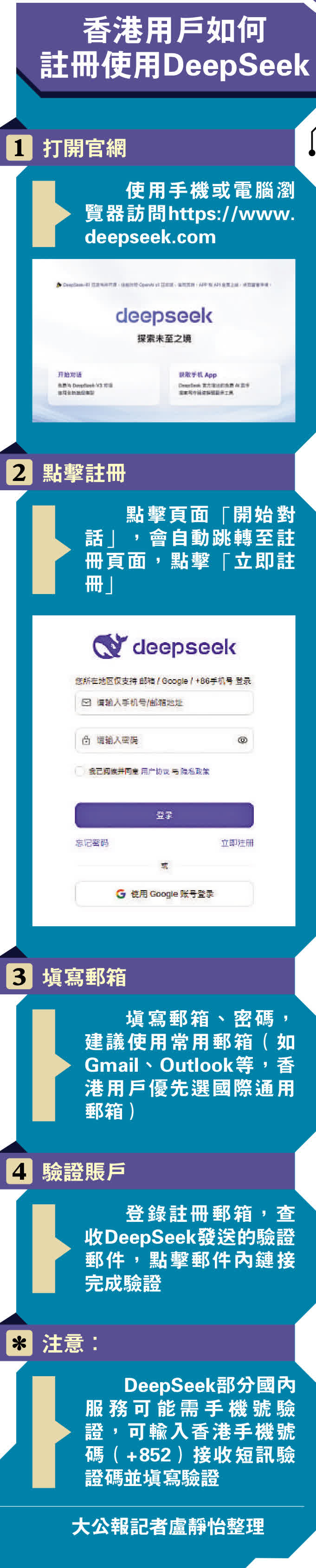
香港用戶如何註冊使用DeepSeek
捕捉AI開源商機 港應善用優勢
科技創新界立法會議員邱達根表示,DeepSeek的出現會進一步推動中國人工智能的全面發展。香港在人工智能領域也具備獨特優勢,主要體現在推動不同專項大模型的研發上。香港擁有豐富的醫療數據和內地工業生產數據,這些數據均為訓練人工智能模型提供了寶貴的資源。「低質數據將嚴重損耗算力效率,香港成熟的數據標準體系與法規框架,正可協助內地開源軟件實現標準化升級,增強市場信任度。」
身兼人工智能科技上市公司戰略顧問的立法會議員尚海龍認為,香港人工智能的優勢在於香港高校創新基礎雄厚,能夠快速跟進甚至引領國際創新科技方向,短板在於產業基礎薄弱,應用市場有限。他建議特區政府一方面要持續培育本地AI人才、盡快推動人工智能作為必備素養進中小學,另一方面,也要善用數以十萬計新來港人才的寶貴資源,挖掘本港創新科技快速轉化,支持AI落地於本港、壯大於灣區、銷售去全球。
選委會界別議員吳傑莊表示,香港AI正處在初始發展期,特區政府已推動自家開發的大語言模型在內部應用,並於去年通過政策支持和資金投入,推動業界加大投入發展AI。然而,香港仍面臨人才短缺和產業鏈不完善等挑戰。他建議鼓勵企業、大學和研究機構之間的合作,共同推動技術創新。對於所謂「技術偷竊」的指控,吳傑莊認為這反映了美國對中國技術崛起的擔憂,以及對市場競爭的焦慮。「在開源協作已成主流的AI領域,知識共享是創新基石。中美更應探索技術共治框架,而非陷入零和博弈。」
話你知|建授權數據生態 利AI創新

使用數據訓練AI大模型,有潛在侵權風險,特別是當訓練數據涉及受版權保護的內容、個人信息或受限制的商業數據。2023年,美國紐約時報起訴OpenAI與微軟,指控ChatGPT在未經授權的情況下複製其文章內容用於訓練,且生成的回答可逐字復現原文段落,侵犯版權。爭議焦點在於,模型輸出是否構成「演繹作品」,以及訓練階段的臨時數據複製是否適用「合理使用」。簡單來說,該案涉及「數據價值分配權」,判決結果將重塑AI行業的數據獲取成本與創新速度。隨着數據抓取時代邁步「合規化」,授權數據生態逐步的建立,對推動AI創新具有重大意義。
什麼是縮放定律?
在人工智能(AI)和深度學習(DL)領域,縮放定律(Scaling Laws)指的是模型性能如何隨計算量、參數規模和數據量的增加而變化的規律。這些定律幫助研究者理解如何提高AI性能,以及是否值得投入更多資源來訓練更大的模型。
如果用「培育一棵樹」的比喻來理解縮放定律,樹的樹根深度即為大模型的模型參數量;土壤養分為訓練數據量,陽光能量為計算資源,果實甜度為模型性能。當樹根更深(模型參數量更大)、土壤更肥(訓練數據量更大)、陽光更足(算力更強),果實會越來越甜(模型性能更強),且甜度提升速度超過投入增長─直到遇到「玻璃天花板」,此時再增加投入,甜度增幅急劇放緩。
就像園林大師不會盲目追求最高樹木,AI工程師通過縮放定律尋找「甜蜜點」:在算力預算內,找到使(性能提升/資源消耗)比值最大的參數─數據─算力組合,這就是DeepSeek以算法突圍而出的關鍵所在。
(來源:大公報A2:要聞 2025/02/01)





